Booleans and B-tree Indexes: A Cautionary Tale
Are you sure your indexes are being used?
Booleans and B-tree Indexes: A Cautionary Tale
Boolean fields are commonplace in most databases. They even featured prominently in my last post, about computed boolean flags . However, when it comes to indexing, they can be a bit tricky. Specially if your database is MySQL.
Indexing - In Theory
On a very high level, a database index allows you to speed up queries by reducing the search space and allowing you to traverse it faster. The mechanics behind them will vary from platform to platform and from index type to index type.
The most common index type for relational databases is a B-tree . Suppose you
have an is_active column in the table that tracks your User objects. Let’s assume
that 80% of your users are active, having is_active = True. A regular B-tree index on that column would split your search space into
two parts - one containing 20% of the records and the other containing 80% of
the records:
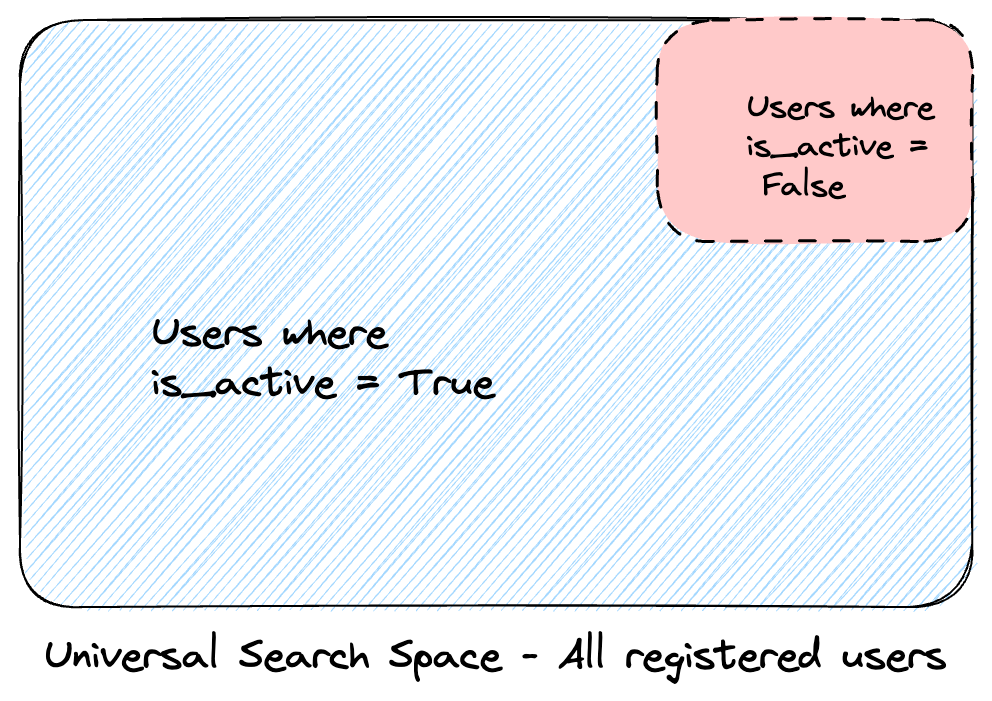
With proper indexing and index usage, searching through inactive users will involve dealing only with the little red region, instead of the whole search space
If you search for records with a False value, for example, the database will
traverse only 20% part of the index to find the records you are looking for.
Indexing - In Practice
Now, B-trees are great, but the devil sometimes lies in the details. When we added an index for a boolean column we saw radically different performance between queries similar to:
SELECT * FROM items WHERE is_deleted = true;and
SELECT * FROM items WHERE is_deleted IS true;You can see a benchmark of that query over random data below, on a test performed by Thomas Jost, a fellow Doister who worked with me on this analysis:
| Run | IS FALSE | = FALSE | |
|---|---|---|---|
| Run 1 | 3,383 | 1,472 | |
| Run 2 | 3,637 | 1,349 | |
| Run 3 | 3,277 | 1,394 | |
| Run 4 | 3,086 | 1,378 | |
| Run 5 | 3,108 | 1,395 | |
| Run 6 | 3,066 | 1,451 | |
| Run 7 | 3,020 | 1,456 | |
| Run 8 | 3,148 | 1,556 | |
| Run 9 | 3,227 | 1,574 | |
| Run 10 | 3,156 | 1,563 | |
| Average | 3,2882 | 1,4588 | -55,64% |
| Median | 3,1915 | 1,4535 | -54,46% |
| Std deviation | 0,2692 | 0,0821 |
From that data, we can infer that something is definitely off with our query. But what? Let’s build a simple example table:
CREATE TABLE `items` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`is_deleted` tinyint(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_is_deleted` (`is_deleted`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;and take a look at the relevant part of the EXPLAIN for the two queries:
Query #1
EXPLAIN SELECT * FROM items WHERE is_deleted IS FALSE;| possible_keys | key | rows | filtered | Extra |
|---|---|---|---|---|
| idx_is_deleted | 1 | 100 | Using where; Using index |
Query #2
EXPLAIN SELECT * FROM items WHERE is_deleted = FALSE;| possible_keys | key | rows | filtered | Extra |
|---|---|---|---|---|
| idx_is_deleted | idx_is_deleted | 1 | 100 | Using index |
The second query uses the index, while the first one does not. Why is that? The
answer lies in the semantics of the IS operator.
Identity vs Equality
In Computer Science it is sometimes important to distinguish between two types of comparisons: identity and equality. The former is the strictest form of comparison, where two objects are equal if and only if they are the same object. The latter is a more relaxed check, where two objects are equal if they have the same value.
This may seem like a trivial distinction, a splitting of hairs that is only relevant for theoreticians and overzealous CS practitioners, but it is quite important. If you ask me for a beer, and I give you a beer, we can say that the values are equal.
However, if you ask me for exactly the beer you bought yesterday, and I give you a beer from my fridge, the identity check fails, even if I give you a beer of the exact same brand you bought.
In practice, the semantics of equalities and identities will vary between different programming languages. If you ponder the complexities behind the question “Is this object the same as that object?”, you can see why.
The difficulties of telling apart identity and equality are more pronounced
if you consider how easy it is for a program to copy parts of its own
memory bit by bit. If x = 10 and y = x, are x and y pointing to the same memory address?
What if a = 10 and b = 10? What if instead of dealing with trivial primitives like
integers, we are dealing with complex objects? The list of questions goes on and on.
What is a Boolean for MySQL
In short, they don’t exist. MySQL does not have a native boolean type.
Instead, it uses the TINYINT type to represent boolean values. As a TINYINT may range
from -128 to 127, MySQL will consider any value that is not 0 as true, and 0 as
false.
As one of our engineers, Artyom Pervukhin, pointed out, the nuance here is that
a query like is_deleted IS True crosses two different worlds - the
numeric realm where is_deleted lives and the boolean realm where True lives.
While IS and = will behave the same for values 0 and 1, they will differ for
any other:
MySQL [todoist_data]> select 0 is true, 0 = true;
+-----------+----------+
| 0 is true | 0 = true |
+-----------+----------+
| 0 | 0 |
+-----------+----------+
1 row in set (0.00 sec)
MySQL [todoist_data]> select 1 is true, 1 = true;
+-----------+----------+
| 1 is true | 1 = true |
+-----------+----------+
| 1 | 1 |
+-----------+----------+
1 row in set (0.00 sec)
MySQL [todoist_data]> select 2 is true, 2 = true;
+-----------+----------+
| 2 is true | 2 = true |
+-----------+----------+
| 1 | 0 | <====== Aha!
+-----------+----------+
1 row in set (0.00 sec)MySQL’s documentation states :
Comparison of dissimilar columns (comparing a string column to a temporal or numeric column, for example) may prevent use of indexes if values cannot be compared directly without conversion.
That is, this crossing between realms will prevent the use of the index.
Besides that, there is a nuanced difference when using expressions like IS TRUE
or IS FALSE. While it may seem that IS TRUE is directly comparing against
the TRUE as an alias for 1, that’s not the complete picture.
MySQL provides three flavors for the IS operator :
-
IS TRUE -
IS FALSE -
IS UNKNOWN
When you use column_name = TRUE, you’re applying the equals (=) operator
between the column value and the literal 1. In contrast, column_name IS TRUE
applies the IS TRUE operator, where TRUE is not a standalone literal
value but part of the syntactic operator.
Conclusion
The conclusion is simple - MySQL will not engage the index if you use IS instead
of =. If you have boolean columns in your codebase and they are indexed, make
sure that your queries and the ones made by your ORM are using the appropriate operator.
The screenshot below showcases the number of slow queries before and after
we applied a system-wide fix, changing all IS operators to =:

The number of slow queries with booleans before and after the fix
This small fix alone was enough to eliminate some performance issues we were seeing under specific loads.
While surprising, this behavior is a known issue . Despite verified by the MySQL team, it is unclear if a fix will ever be implemented.
Lastly, it is worth noting that our tests further showed that:
- B-tree indexes are engaged in comparisons using
IS NULLin MySQL - Maria DB is also affected by this issue
- PostgreSQL is not (see DB Fiddle )
Acknowledgments
I would like to thank Thomas Jost, Artyom Pervukhin, Alex Rodrigues, and Gonçalo Silva for their help in researching and fixing this issue, as well as for their feedback on this post.